문제
H-Index는 과학자의 생산성과 영향력을 나타내는 지표입니다. 어느 과학자의 H-Index를 나타내는 값인 h를 구하려고 합니다.
어떤 과학자가 발표한 논문 n편 중, h번 이상 인용된 논문이 h편 이상이고 나머지 논문이 h번 이하 인용되었다면 h의 최댓값이 이 과학자의 H-Index입니다.
어떤 과학자가 발표한 논문의 인용 횟수를 담은 배열 citations가 매개변수로 주어질 때, 이 과학자의 H-Index를 return 하도록 solution 함수를 작성해주세요.
제한조건
- 과학자가 발표한 논문의 수는 1편 이상 1,000편 이하입니다.
- 논문별 인용 횟수는 0회 이상 10,000회 이하입니다.
입출력 예
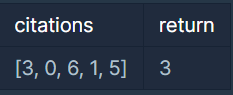
풀이
이 문제는 H-Index를 먼저 이해해야 풀이가 가능한 문제입니다. 먼저 H-Index의 정의는 다음과 같습니다.
💡 H-Index란?
h - index 는 처음에 개별 과학 자나 학자 에게 사용된 출판물의 생산성 과 인용 영향 을 모두 측정 하는 저자 수준 측정항목 입니다.
h -index는 주어진 저자/저널이 각각 최소 h 회 인용된 최소 h 개의 논문을 출판 한 h 의 최대값으로 정의됩니다 . 이 지수는 총인용수나 출판물 수와 같은 단순한 척도를 개선하기 위해 고안되었다. 동일한 분야에서 일하는 학자들을 비교할 때 색인이 가장 잘 작동합니다. 인용 규칙이 분야마다 크게 다르기 때문입니다
이러한 H-Index는 어떻게 계산할 수 있을까요? 이 문제의 예시를 이용하여 계산하는 방법을 알아보겠습니다.
먼저 [3, 0, 6, 1, 5] 이라는 리스트가 있고, H-Index 계산을 하기 위해서 먼저 내림차순으로 정렬을 해주어야 합니다. 내림차순으로 정렬하면 [6, 5, 3, 1, 0] 의 순서가 됩니다. 여기서 리스트n 번째 값이 최초로 n을 넘지 않을 때, n-1의 값이 H-Index 값이 됩니다. 이것을 표로 나타내면 아래와 같습니다.
| 순번 | N번째 리스트 값 | 기준 값 |
| 1 | 6 | 6 > 1 (X) |
| 2 | 5 | 5 > 2 (X) |
| 3 | 3 | 3 = 3 (X) |
| 4 | 1 | 1 < 4 (O) |
| 5 | 0 |
여기서 3번째 까지 리스트의 값이 순번보다 크거나 같지만, 4번째의 경우 리스트의 값이 순번보다 작기 때문에, 기준 값은 조건에 부합하는 마지막 순번이었던 3이 됩니다.
이제 이를 활용하여 리스트의 각 값이 기준 값보다 크거나 같은지를 판별하면 됩니다. 위의 표에서는 [6, 5, 3] 이 기준 값인 3보다 크거나 같으므로 H-Index의 값은 3이 됩니다.
여기서 H-Index를 구해도 무방하지만, 다시 생각해보면 리스트의 값이 내림차순으로 정렬이 되어있기 때문에 기준이 되는 순번에 -1을 해주면 H-Index 값이 되는 것을 알 수 있습니다. 이렇게 되면 소스코드로 구현시 H-Index로 구현하기 위해 반복문을 한번 더 사용하지 않아도 되기 때문에 훨씬 효율적으로 코드를 작성할 수 있습니다.
위 풀이를 기준으로 작성한 소스코드는 다음과 같습니다.
def solution(citations):
answer = 0
citations.sort(reverse=True) # 내림차순으로 정렬
for i in range(len(citations)):
if(citations[i] < i+1): # H-Index 값을 구하기위해 비교
answer = i # 찾으면 i 값(n-1)이 H-Index 값
break
return answer
문제없이 잘 통과할 줄 알았으나..... 테스트 9번만 통과하지 못했습니다. (반례를 찾아야 되네요....ㅠㅠ)
이럴 경우 제가 보통 많이 생각하는 것이 리스트의 값이 모두 같은 값일 때의 경우입니다. 이를 생각하여 [5,5,5,5] 이라는 리스트가 있다고 가정하고 H-Index를 구해보겠습니다.
| 순번 | N번째 리스트 값 | 기준 값 |
| 1 | 5 | 5 > 1 (X) |
| 2 | 5 | 5 > 2 (X) |
| 3 | 5 | 5 > 3 (X) |
| 4 | 5 | 5 > 4 (X) |
이렇게 되면 리스트의 길이가 4이고, 모든 리스트의 인용 값이 5이기 때문에 H-Index의 값은 4가 되어야 합니다. 하지만 위의 소스코드를 기준으로 테스트를 해보면 H-Index의 값은 0이 됩니다. 아마도 테스트 9번이 통과하지 못한 것이 이 때문이지 않을까 생각하고, 수정한 소스코드는 다음과 같습니다.
def solution(citations):
answer = 0
citations.sort(reverse=True)
for i in range(len(citations)): # H_index가 존재하고 H_index를 넘는 논문이 몇 개인지 구할때
if(citations[i] < i+1):
return i
return len(citations) # 인용 횟수가 모두 같을때는 전체를 return
이와 같이 코드를 작성하면 모든 테스트 케이스를 통과하는 것을 확인할 수 있습니다.
'Algorithm > Python, C++' 카테고리의 다른 글
| [프로그래머스] 짝지어 제거하기(python) (0) | 2023.01.20 |
|---|---|
| [프로그래머스] 숫자 짝꿍(python) (0) | 2022.12.15 |
| [프로그래머스] 구명보트(python) (0) | 2022.09.21 |
| [프로그래머스] 가장 큰 수(python) (1) | 2022.09.19 |
| [프로그래머스] 더 맵게(python) (0) | 2022.09.16 |




댓글